deeplearning-arcgis
Mask R-CNN
La segmentación de instancias de objetos integra tareas de detección de objetos donde el objetivo es dectectar objetos dentro de una caja delimitadora y tareas de segmentación semántica que clasifica cada píxel en categorías predefinidas. De forma que podemos detectar objetos en una imagen a la vez que segmentamos una máscara para cada instancia de objeto.
La segmentación de instancias nos permite hacer tareas como detectar daños conociendo su alcance, la generación de huellas de edificios…
Arquitectura Mask R-CNN
Mask R-CNN es un modelo de segmentación de instancias desarrollado a partir de Faster R-CNN.
Faster R-CNN es una red neuronal convolucional basada en regiones que devuelve cuadros delimitadores para cada objeto y su etiqueta con un grado de confianza.
La arquitectura de Faster R-CNN trabaja en dos etapas:
-
El primer paso consiste en dos redes: backbone (ResNet, VGG, etc) y una red de propuestas regionales. Estas redes se ejecutan una vez por imagen para obtener un conjunto de propuestas de regiones que son regiones del mapa de características que contienen el objeto.
-
En el segundo paso la red predice las cajas delimitadoras y la clase de objeto para cada una de las regiones propuestas en el paso 1. Cada región propuesta puede tener un tamaño diferente, mientras que las capas conectadas de las redes siempre requieren un vector de tamaño fijo para realizar predicciones. El tamaño de las regiones propuestas se fija utilizando el método RoI pool o RoIAlign.

Faster R-CNN predice la clase de objeto y los cuadros delimitadores. Mask R-CNN es una extensión de Faster R-CNN con una rama adicional para predecir máscaras de segmentación en cada región de interés (RoI).
En el segundo paso de Faster R-CNN, RoI pool se sustituye por RoIAlign que ayuda a conservar la información espacial que se desalinea con RoI pool. RoIAlign utiliza la interpolación binaria para crear un mapa de características de tamaño fijo, p.e. 7x7.
La salida de la capa RoIAlign se introduce en Mask head que consta de dos capas de convolución y genera una máscara para cada RoI, segmentando una imagen píxel a píxel.

PointRend Enhancement
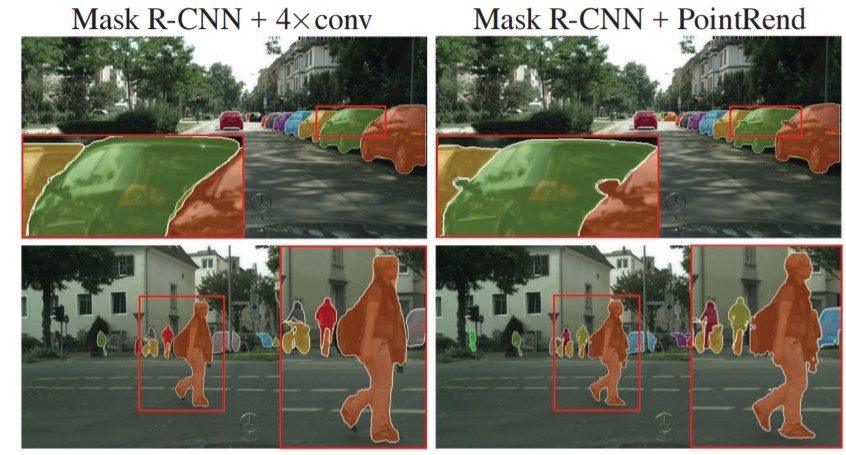
Los modelos de segmentación tienden a generar límites demasiado suaves lo que puede hacer que no sean precisos para los objetos. Para obtener un límite de segmentación nítido, se ha añadido al modelo un módulo de red neuronal de renderizado basado en puntos llamado PointRend. Este módulo aporta perspectiva de renderizado a la segmentación de objetos obteniendo así resultados de alta resolución de forma eficiente.
Para usar esta mejora hay que definirla junto al modelo:
model = MaskRCNN(data=data, pointrend=True)
Modelos pre-entrenados del Living Atlas
Algunos modelos que usan este algoritmo son: