deeplearning-arcgis
PSPNet
PSPNet (Pyramid scene parsing network) es otro modelo de segmentación semática implementado en el módulo de arcgis.learn junto a U-Net que nos permite clasificar píxeles.
El PSPNet es una mejora respecto a la segmentación basada en FCN (Fully Convolutional Network - redes totalmente convolucionales) porque tiene en cuenta el contexto global de la imagen en las predicciones locales.
Se entiende mejor con el ejemplo:

En este caso, podemos ver como el FCN clasifica el barco que aparece en la imagen (a) con un recuadro amarillo como coche. Esto lo hace porque por forma y tamaño un coche y un barco son parecidos, pero si el modelo hubiera tenido en cuenta el contexto (el río) lo hubiera clasificado como barco como ha hecho PSPNet (d).
Arquitectura Encoder-Decoder para la segmentación semántica
La mayoría de los modelos de segmentación semántica tienen dos partes, un Encoder y un Decoder.
- Encoder: responsable de la extracción de elementos de la imagen.
- Decoder: el que predice la clase de cada píxel.

PSPNet Encoder
El encoder de PSPNet contiene el backbone de la CNN con convoluciones dilatadas junto con la agrupación piramidal.
Convoluciones dilatadas o convoluciones con agujeros
Las convoluciones dilatadas se caracterizan porque se introduce un espacio entre los elemento del filtro de convolución o kernel. Esto permite aumentar el campo recepctivo de la red sin aumentar la cantidad de parámetros ni el tamaño del kernel. Esto permite capturar información contextual de la imagen que se está procesando.
Este tipo de capas se suele añadir en las últimas capas del backbone, sustituyendo las convoluciones tradicionales, aumentando el campo receptivo.
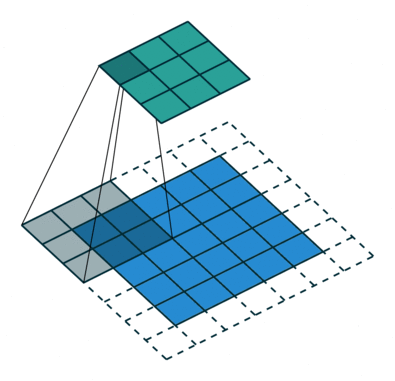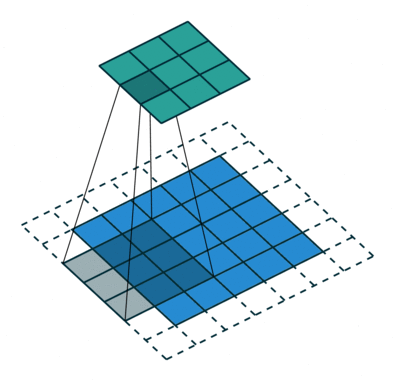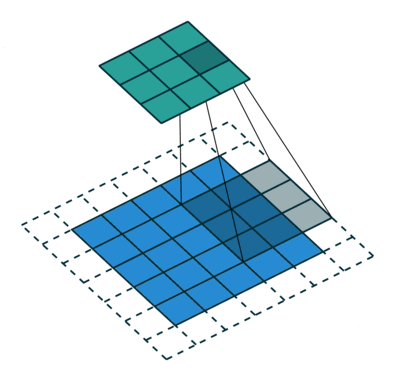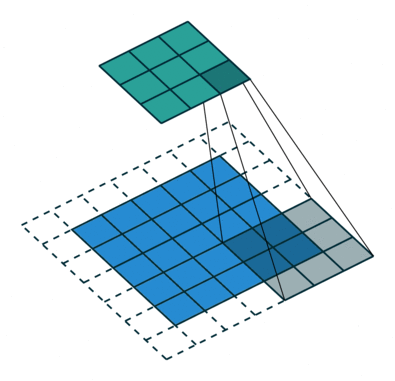
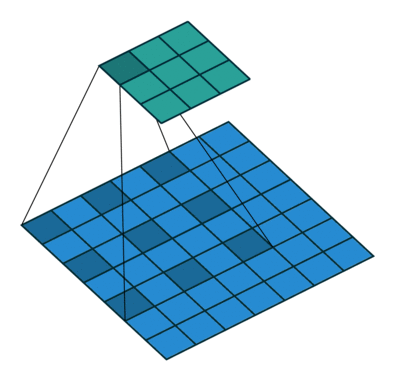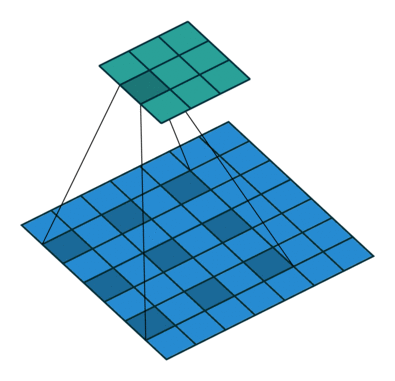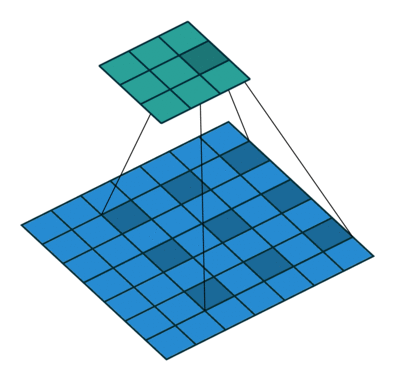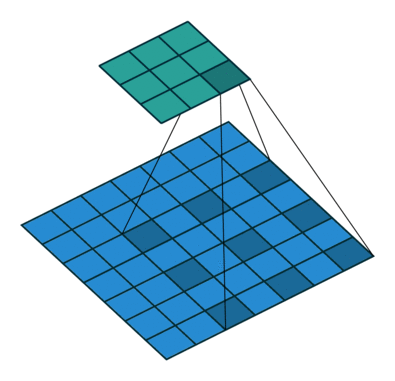
La animación de la izquierda tienen una dilatación de 1 (operación normal) y la de la derecha de 2.
El valor de dilatación especifica la dispersión y está relacionado directamente con el campo receptivo. El tamaño del campo receptivo indica cuánta información contextual utilizamos. En PSPNet, los dos últimos bloques tienen unos valores de dilatación de 2 y de 4.
Pyramid Pooling Module - Módulo de agrupación piramidal
El módulo de agrupación piramidal es la parte principal del modelo ya que ayuda a captar el contexto global de la imagen lo que ayuda a clasificar los píxeles basándose en la información global presente en la imagen.
La agrupación (pooling) piramidal se realiza en paralelo a varias escalas lo que permite capturar información contextual a diferentes niveles de detalle en la imagen. Una vez que la información está agrupada por tamaño, se reduce la dimensionalidad y combina la información de diferentes escalas. Tras ello, se realiza un proceso de upsampling (aumento del tamaño espacial) de esos mapas de características resultantes para que todos tengan el mismo tamaño que el mapa original del backbone. Esos mapas se concatenan con el mapa original y por último, se pasa al decoder, la parte responsable de generar el resultado final generando predicciones precisas y detalladas.

Por ejemplo, en la imagen podemos ver:
- Feature Map: el mapa de características que devuelve las capas convolucionales “normales”.
- Los cuatro colores representan diferentes escalas: 6, 3, 2 y 1 (verde, azul, naranja y rojo). El mapa de características se agrupa en esas escalas definidas.
- Esos elementos agrupados se les aplica una red convolucional con filtros 1x1 para reducir la profundidad de las características.
- Esos elementos se remuestrean (upsample) al tamaño del mapa de características y se concatenan.
- Como regla general, si el tamaño de la pirámide es pequeño, es decir, ~1 o 2, el modelo captará las características de baja resolución y de mayor tamaño, mientras que si el tamaño de la pirámide es mayor, es decir, ~6-8, el modelo podrá captar las características de alta resolución.
Viene a ser como que se estiran las imágenes por eso se pierde calidad de imagen y resolución.
PSPNet Decoder
Después de que el encoder haya extraído las características de la imagen, el decoder tiene que coger esas características y convertirlas en predicciones.
El modelo PSPNet no es un modelo de segmentación completo en sí mismo, es solo un codificador, lo que significa que es solo la mitad de lo que se necesita para la segmentación de imágenes. Los decodificadores más comunes son una capa de convolución seguida de un muestreo bilineal 8x.

El problema de tener un decoder 8x upsampling es que no hay parámetros que se puedan aprender por lo que los resultados que obtenemos son borrosos y no se consigue capturar información de alta resolución.
PSPNet con U-Net como decoder
Para obtener un resultado de alta resolución, una forma es tener un decoder que tenga parámetros aprendibles y pueda tomar características intermedias del encoder como entrada.

Salto de conexiones del encoder al decoder tipo U-Net
Para conseguirlo se puede utilizar el decoder de red piramidal de características (FPN) que es el que se utiliza también con U-Net. Así se consigue añadir el decoder FPN al encoder PSPNet que peude capturar las pequeñas características de la imagen.
Mejora con PointRend
Los modelo de segmentación tienden a crear border suaves lo que hace que no sean muy precisos para objetos con límites irregulares. Para obtener unos límites de segmentación nítidos, se puede añadir al modelo un módulo de red neuronal de renderizado basado en puntos PointRend (como con U-Net). Este módulo aporta perspectiva del renderizado a la segmentación pudiendo obtener resultados de alta resolución de forma eficiente.

Implementación con arcgis.learn
El módulo de arcgis.learn nos permite implementar el modelo PSPNet.
from arcgis.learn import PSPNetClassifier
psp = PSPNetClassifier(data=data)
Y también, ajustar todos estos parámetros/configuraciones que hemos revisado:
Ajustar las escalas Con el parámetro pyramid_sizes podemos ajustar los valores en los que queremos que el modelo agrupe las características del mapa de características. Por defecto, los valores son 1, 3, 5 y 6 (los más utilizados), pero podemos cambiarlo en función de nuestro conjunto de datos, es decir, si tenemos una gran variación en el tamaño de las características a segmentar, podemos aumentar el número de pirámides y su tamaño, mientras que, si tenemos características de tamaño similar, podemos usar una sola pirámide o dos niveles.
Clasificador PSPNet con 8x upsampling decoder Por defecto, se crea un decoder FPN al implementar el modelo PSPNetClassifier. Pero podemos crear un clasificador PSPNet con decoder 8x upsampling con el parámetro use_unet:
psp = PSPNetClassifier(data=data, use_unet=False)
Mejora con PointRend Con el parámetro pointrend podemos inicializar el modelo con el módulo PointRend que mejore la segmentación de la imagen.
psp = PSPNetClassifier(data=data, pointrend=True)