deeplearning-arcgis
RetinaNet
Es uno de los mejores modelos de detección de objetos en una sola pasada con objetos densos y a pequeña escala. Es un modelo de detección de objetos muy utilizado en imágenes aéreas y de satélite.
RetinaNet se ha formado a partir de dos modelos de detección de una etapa: Feature Pyramid Networks (FPN) y Focal Loss.
FPN Tradicionalmente, FPN es utilizado para detectar objetos en una imagen a diferentes escalas. Lo que significa que se toma una imagen y se submuestrea en imágenes de menor resolución y tamaño formando así una pirámide. A continuación, se extraen las características a mano de la pirámide capa a capa para detectar objetos.
Con el avance del deep learning, esa extracción a mano ha sido reemplazada por redes CNN. En una arquitectura CNN, el tamaño de salida de los mapas de características desciende después de los bloques sucesivos de operaciones convolucionales formando una pirámide.
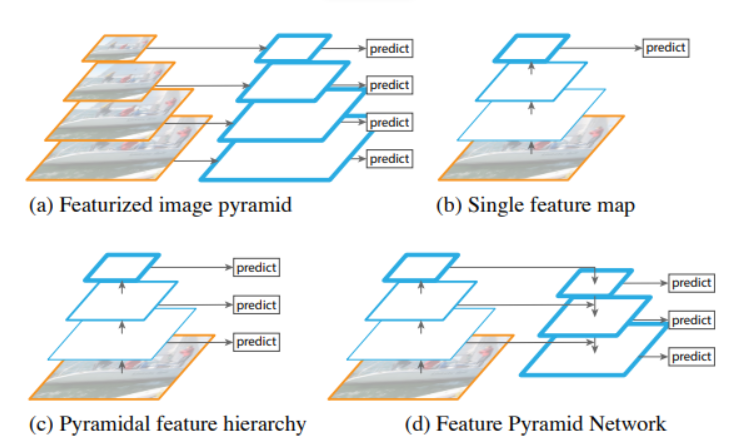
En la imagen se ven diferentes arquitecturas FPN: a. Featurized image pyramid: es muy intensiva computacionalmente. b. Single (scale) feature maps: se usaba para detecciones rápidas. c. Pyramidal feature hierarchy: arquitectura usada en modelos como SSD, pero no reutiliza las capas de características multiescala de diferentes capas. d. Feature Pyramid Network (FPN): compensa las deficiencias de las variantes. FPN crea una arquitectura semántica rica en todos los niveles al combinar características semánticamente fuertes de baja resolución con características semánticamente débiles de alta resolución.
Focal Loss (FL) Focal Loss es una mejora de la pérdida de entropía cruzada (Cross-Entropy Loss - CE) y se añadió para solventar el problema del desequilibrio de clases en los modelos de una sola etapa.
El problema de desequilibrio de clases entre el primer plano y el fondo debido al denso muestro de cajas de anclaje, es decir, posibles ubicaciones de objetos. En RetinaNet puede haber miles de cajas de anclaje en cada capa piramidal aunque solo a unas pocas se les asignarán un objeto verdadero mientras que la mayoría corresponderá a la clase de fondo. Estas detecciones de alta probabilidad puede dar lugar a pequeños valores de pérdida que abrumen al modelo. Justamente la pérdida focal reduce la contribución de esas pérdidas y aumenta la importancia de corregir los ejemplos mal clasificados.
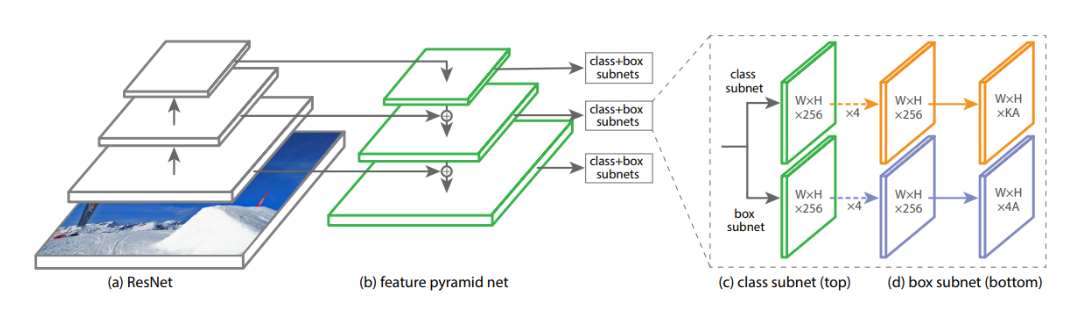
Arquitectura RetinaNet
Hay cuatro componentes principales en esta arquitectura:
- Patrón ascendente: La red backbone que calcula los mapas de características a diferentes escalas, independientemente del tamaño de la imagen de entrada o del backbone.
- Patrón descendente y conexiones laterales: la vía descendente muestrea los mapas de características espacialmente más gruesos de los niveles superiores de la pirámide y las conexiones laterales fusionan las capas con el mismo tamaño espacial.
- Subred de clasificación: predice la probabilidad de que un objeto esté presente en cada ubicación espacial para cada caja de anclaje y clase de objeto.
- Subred de regresión: desplaza los recuadros delimitadores desde las cajas de anclaje para cada objeto verdadero.
Implementación con la ArcGIS API for Python
Para crear el modelo solo necesitamos el módulo arcgis.learn:
model = RetinaNet(data)
Aunque podemos pasar más parámetros como:
- data: preparados en pasos anteriores.
- backbone: de la familia de ResNet. El valor por defecto es ResNet50.
- scales de las cajas de anclaje.
- Aspecto de ratios de las cajas de anclaje.
El ajuste de estos parámetros se basa en la intuición adquirida a través de la comprensión del modelo y la experimentación con el conjunto de datos.