deeplearning-arcgis
Single-Shot Detector
Se trata de un algoritmo que solo realiza una pasada por la imagen a analizar.
El SSD (Single-Shot Detector) tiene dos componentes:
- El modelo troncal (backbone model): suele ser una red de clasificación de imágenes pre-entrenada como extractor de elementos. Normalmente se trata de una red como ResNet entrenada en ImageNet. De esta forma se obtiene una red neuronal profunda capaz de extraer el significado semánticos de la imagen de entrada.
- El cabezal SSD (SSD head): es una o varias capas convolucionales añadidas al backbone. Los resultados se interpretan como cuadros delimitadores y clases de objetos en una ubicación espacial.
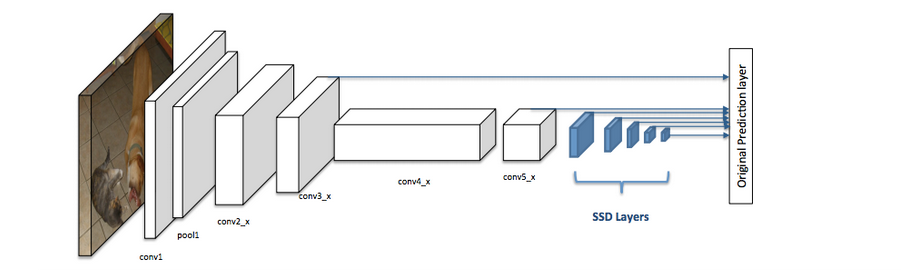
Las cajas blancas representan las primeras capas del backbone y las cajas azules el cabezal SSD.
Malla de celdas SSD divide la imagen utilizando una cuadrícula y hace que cada celda de la cuadrícula sea responsable de detectar objetos en esa region de la imagen. Detectar objetos significa predecir la clase (elemento) y la ubicación del objeto dentro de la región. Si no hay ningún objeto, se considerará como la clase de fondo y se ignorará la ubicación.
Pero, ¿qué pasa si hay varios objetos en una celda de la cuadrícula o si los objetos que detectamos tienen formas diferentes? La respuesta es la caja de anclaje y campo de recepción.
Caja de anclaje o anchor box
Cada celda de la cuadrícula puede ser asignada con múltiples cajas de anclaje. Esas cajas están predefinidas y cada una es responsable de un tamaño y una forma dentro de cada celda de la cuadrícula.
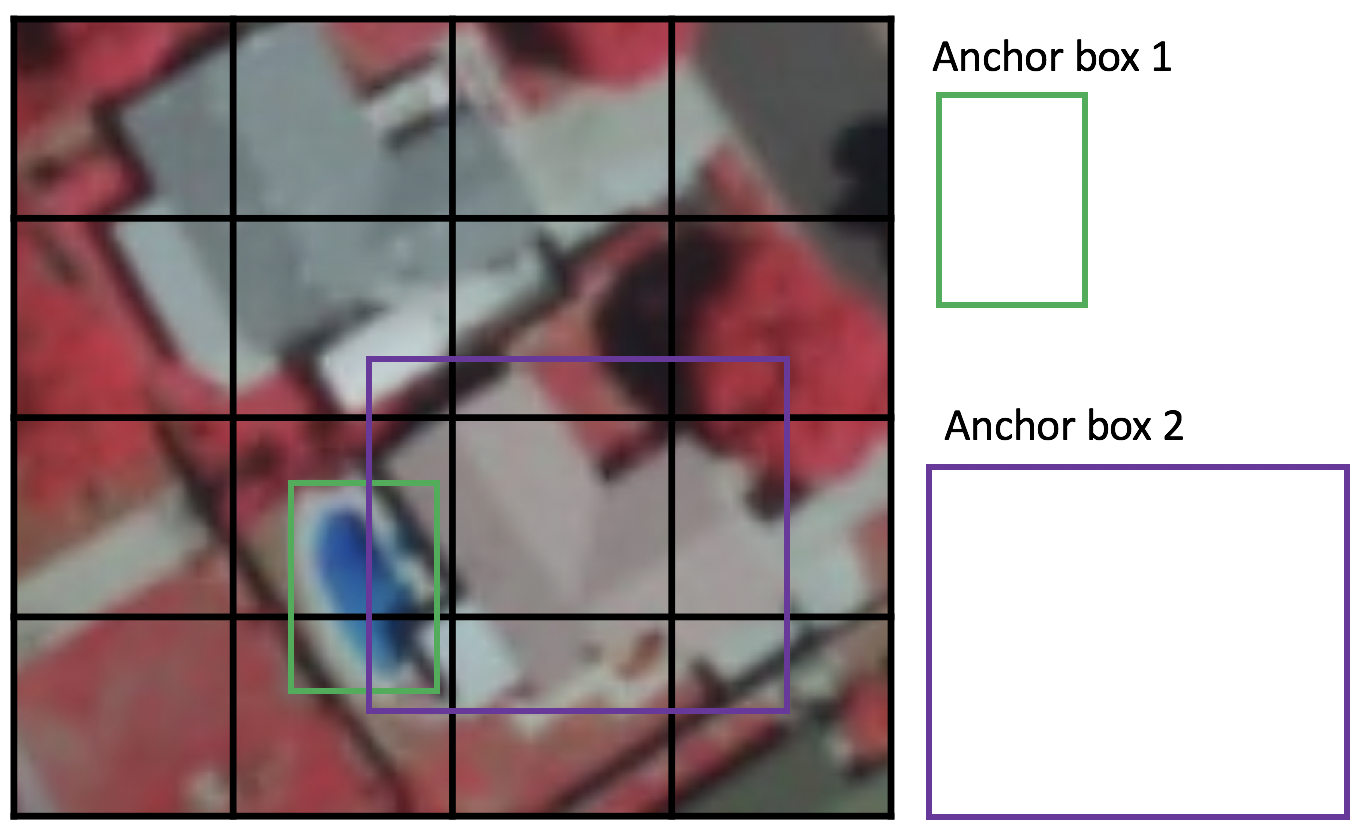
Durante el entrenamiento, SSD utiliza una fase de correspondencia para hacer coincidir el cuadro de anclaje apropiado con los cuadros delimitadores de cada objeto. En esencia, el cuadro de anclaje con el mayor grado de solapamiento con un objeto es el responsable de predecir la clase de ese objeto y su ubicación.
Relación de aspecto
No todos los objetos tienen una forma cuadrada. Para tener esto en cuenta, la arquitectura SSD permite relaciones de aspecto predefinidas de los cuadros de anclaje. El parámetro de ratios puede utilizarse para especificar las diferentes relaciones de aspecto de los cuadro de anclaje asociados a cada celda en cada nivel de zoom o escala.
Nivel de zoom
No es necesario que los cuadro de anclaje tengan el mismo tamaño que la celda de la cuadrícula.
Campo receptivo o receptive field
Es la región del espacio de entrada en la que se fija un determinado elemento de la CNN. Debido a la operación de convolución, los elementos de las distintas capas representan distintos tamaños de región en la imagen de entrada. A medida que se profundiza, el tamaño de un elemento se hace mayor.
En este ejemplo comenzamos en la capa de abajo (azul) (5x5) y luego aplicamos una convolución que da como resultado la capa media (verde) (3x3) donde un elemento (píxel verde) representa una región de 3x3 en la capa de entrada (capa inferior/azul). Luego, al aplicar la capa de convolución a la capa media y obtener la capa superior (amarilla) (2x2) cada característica corresponde a una región 7x7 en la imagen de entrada.
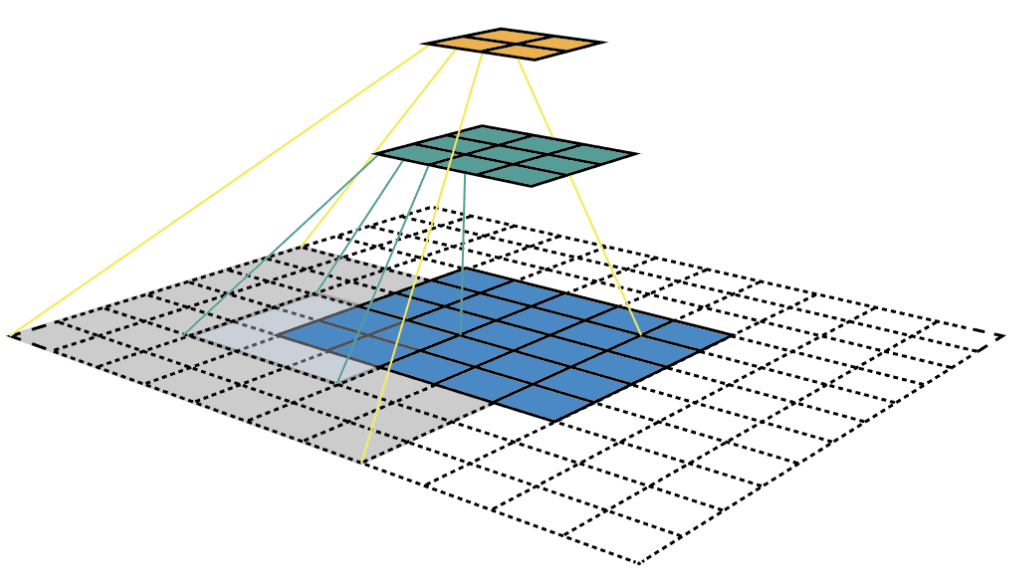
Este tipo de matrices 2D (capas amarilla y verde) formadas a partir de la imagen de entrada se denominan mapas de características que se refieren a un conjunto de características creadas aplicando el mismo extractor de elementos en diferentes ubicaciones del mapa de entrada. Las características del mismo mapa de características tienen el mismo campo receptivo y buscan el mismo patrón pero en diferentes ubicaciones. Esto crea la invariancia espacial de ConvNet.
El campo receptivo es la premisa central de la arquitectura SSD ya que es la que nos permite detectar objetos a diferentes escalas y obtener un cuadro delimitador más ajustado.
Como tal vez recuerde, la columna vertebral de ResNet34 genera 256 mapas de características de 7x7 para una imagen de entrada. Si especificamos una cuadrícula de 4x4, el enfoque más sencillo es simplemente aplicar una convolución a este mapa de características y convertirlo a 4x4. Este enfoque puede funcionar hasta cierto punto y es exactamente la idea de YOLO (You Only Look Once). El paso adicional que da SSD es que aplica más capas convolucionales al mapa de características principal y hace que cada una de estas capas convolucionales produzca un resultado de detección de objetos. Como las capas anteriores con un campo receptivo más pequeño pueden representar objetos de menor tamaño, las predicciones de las capas anteriores ayudan a detectar objetos de menor tamaño.
Por ello, SSD nos permite definir una jerarquía de celdas de cuadrícula en diferentes capas. Por ejemplo, podríamos utilizar una cuadrícula 4x4 para encontrar objetos pequeños, una cuadrícula 2x2 para encontrar objetos de tamaño medio y una cuadrícula 1x1 para encontrar objetos que cubran toda la imagen.
Implementación con ArcGIS API for Python
Con el módulo de arcgis.learn de la API podemos definir la arquitectura del modelo en una sola línea:
ssd = SingleShotDetector(data, grids=[4], zooms=[1.0], ratios=[[1.0, 1.0]])
Los parámetros que le hemos pasado son:
- El tamaño de la celda de la cuadrícula, en este caso 4x4.
- Nivel de zoom de 1.0
- Relación de aspecto 1.0:1.0 lo que significa que la red creará una caja de anclaje para cada celda de la cuadrícula del mismo tamaño que la celda de la cuadrícula y de forma cuadrada por su relación de aspecto.